


前々回と前回の記事では、Pythonのスクレイピング を活用して、WEB上にある記事を効率よくピックアップする方法について解説しました。
-

-
関連記事【Python】スクレイピング で効率よく記事を読もう!その1
続きを見る
-
-
関連記事【Python】スクレイピング で効率よく記事を読もう!その2
続きを見る
ピックアップした記事の中には、いいな!とか勉強になるな!という記事があります。
そんな記事はしばらくの間、保存しておきたいですよね。
もちろんPythonを使えば、スクレイピングでピックアップした記事を簡単に保存することができます。
よって今回はー
スクレイピングでピックアップした記事を保存する方法
について解説します。
使うライブラリは、これまでと同じく『newspaper3k』です。
この記事を読んでわかること
わかること
- スクレイピングでピックアップした記事を保存する方法
この記事の対象となる人
こんな人におすすめ
- プログラミング言語『Python』に興味がある人
- Pythonを使って効率的に情報を得たい人
結論からいいます
- Pythonを使えば効率的に情報を得ることができる
- スクレイピングを使えばWEB上の記事をピックアップできる
- ピックアップした記事を保存することができる
情報取集の基本『スクレイピング』

スクレイピングとは?
まずは復習です。
スクレイピングとはー
- Web上にあるデータを取得すること
- 取得したデータをスプレッドシートやデータベースに格納したり編集したりすること
スクレイピングを使えば、WEB上に存在するあらゆるデータを取得することができます。
しかし注意すべきこともあります。
スクレイピングを学ぶ前に、この点についてはしっかりと覚えておいてください。
注意すべきこと
- WEBサイトによってはスクレイピングでのアクセスを制限していることがある
- アクセスの頻度によっては違法な攻撃として法的に処罰されてしまう可能性がある
なお、スクレイピングでデータが取得できないサイトでは、『API(Application Programming Interface)』を活用することで、欲しいデータを取得できる場合があります。
しかしAPIには、無料のケースと有料のケースがあります。
よって、APIでデータを取得する場合は、必ずデータを提供しているサイトに料金設定の確認をすることをおすすめします。
実践!Pythonでスクレイピング

さて、今回はブルームバーグのトップサイトに掲載されている記事をピックアップし、それを保存する方法について解説します。
まずはブルームバーグの記事をピックアップ!
まずは、スクレイピングでブルームバーグのトップサイトに掲載されいている10記事をピックアップしてみましょう。
これは、前々回の復習となります。詳細については以下のリンク先からご覧ください。
-
-
関連記事【Python】スクレイピング で効率よく記事を読もう!その1
続きを見る
詳細は抜きにして、まずはPythonのコードをご紹介します。
Pythonのコード例:記事のピックアップ
import newspaper
import nltk
nltk.download('punkt')
url = 'https://www.bloomberg.co.jp/'
i = 1
for a in website.articles:
a.download()
a.parse()
a.nlp()
print('記事', str(i),':',a.title)
print(a.url)
print(a.summary, end = '\n\n')
if i > 9:
break
i = i + 1
上のコードを実行すると以下の結果がでます。
実行結果


日本語版ブルームバーグのサイトより(2021年2月24日)
10記事までの記事番号、タイトル、リンク先(URL)さらには記事の内容まで、一瞬で取得できました。
Pythonでプログラミングを設定していれば、たったの数秒でブルームバーグのトップサイトに掲載されている記事の内容までが、一気に確認できるというわけです。
次はコードの説明です。
コードの説明
1:記事のデータを読み込むためのライブラリには、前回とおなじく『newspaper3k』を使います
#スクレイピングで必要なライブラリ
import newspaper
#日本語で記事を取得/表示するために必要なライブラリ
import nltk
nltk.download('punkt')
なお、前々回の記事でも言いましたが、newspaper3kはインストールが必要です。
- pipを利用してインストールする場合は、以下のコマンドを入力
pip install newspaper3k
- condaを利用してインストールする場合は、以下のコマンドを入力
conda install -c conda-forge newspaper3k
2:情報を取得するサイトのURLを指定します
ここでは、ブルームバーグのトップページのURLを変数『url』に入れます
url=''https://www.bloomberg.co.jp/'
3:最後の仕上げに、記事の番号を割り振り、タイトル、リンク先さらには記事の内容までを一気に取得するコードを書きます
#記事番号の設定 / はじめの記事を番号『1』とする
i = 1
# for文でブルームバーグの記事データをカウンタ変数『a』にひとつひとつ入れていくコード
for a in website.articles:
#記事のデータをダウンロードする
a.download()
#取得した記事のデータを解析する
a.parse()
#取得した記事のデータを言語化する
a.nlp()
#ピックアップした記事を表示するコード
#記事 → URL → 記事の内容の順で表示するようコードを書く
print('記事', str(i),':',a.title)
print(a.url)
print(a.summary, end = '\n\n')
#10記事取得したらスクレイピングを止めるコード
if i > 10:
break
#記事のデータをひとつ取得するごとに記事番号を一つずつ足していくコード
i = i + 1
ここまでが、前回までの復習です。
スクレイピングでピックアップした記事を保存してみよう!

さて、ここからが今回の本題です。
スクレイピングで取得したブルームバーグの10記事を、エクセルのファイルに保存してみましょう。
まずは、参考となるコードを一気にご紹介。
Pythonのコード例:データの保存
import csv
import datetime
csv_date = datetime.datetime.today().strftime('%Y%m%d')
csv_name = 'BBG_articles' + csv_date +'.csv'
csv_header = ['記事番号','タイトル','URL','サマリー']
f = open(csv_name,mode='w', encoding='utf_8_sig',errors='ignore')
writer = csv.writer(f, lineterminator = '\n')
writer.writerow(csv_header)
i = 1
for a in website.articles:
csv_list = []
a.download()
a.parse()
a.nlp()
print('記事', str(i),':',a.title)
print(a.url)
print(a.summary, end = '\n\n')
csv_list.append(str(i))
csv_list.append(a.title)
csv_list.append(a.url)
csv_list.append(a.summary)
writer.writerow(csv_list)
if i > 10:
break
i = i + 1
f.close()
実行結果
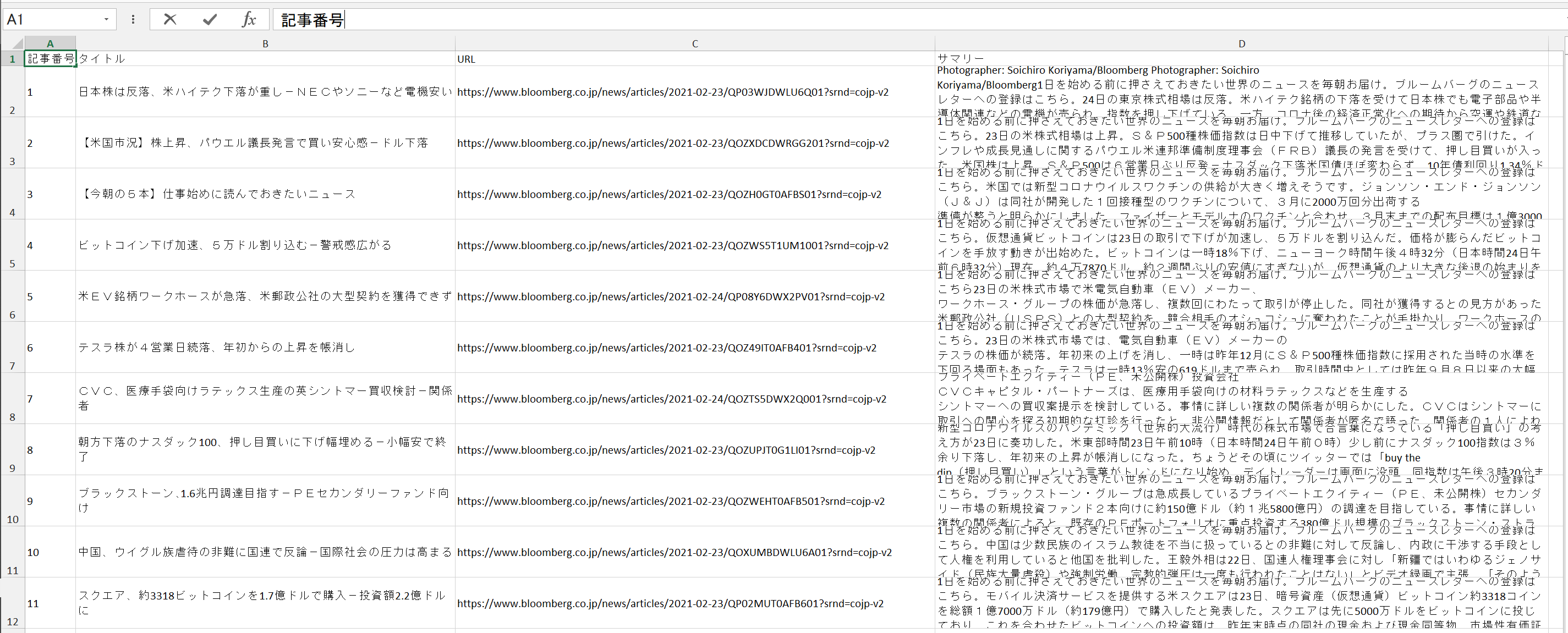
一度コードを書けば、あとは実行するだけで取得したブルームバーグの記事データをエクセルファイルに保存することができました。
繰り返しになりますが、ここまでかかった時間はほんの数秒です。
次にコードの説明です。
コードの説明
1:まずはライブラリのインポートから
#エクセルファイルに書き出すためのライブラリ import csv #日付を設定するライブラリ import datetime
2:次にファイルの各種設定をします
#ファイルの日付を設定する
csv_date = datetime.datetime.today().strftime('%Y%m%d')
#ファイルの名前を設定する
csv_name = 'BBG_articles' + csv_date +'.csv'
#ファイルのヘッダーを設定する
csv_header = ['記事番号','タイトル','URL','サマリー']
3:次にデータを保存するためのファイルのオブジェクトを設定します
#ファイルオブジェクトの設定 f = open(csv_name,mode='w', encoding='utf_8_sig',errors='ignore')
なお、openの 引数を4つ設定していますので、それぞれの意味について簡単に説明しておきます。
・csv_name:ファイル名の指定
・mode='w':”データを書き込んで”という指定 / wは『wrtite』という意味
・encoding='utf_8_sig':表示する言語の選択/ ここでは『utf_8_sig』か『cp932』を選択
・errors='ignore':エラーが出ても無視してくださいという意味のコード
4:ファイルのオブジェクトに取得したデータを書き込む設定をします
#CSVファイルへの書き込み writer = csv.writer(f, lineterminator = '\n') #CSVファイルに1行ずつ書き込む writer.writerow(csv_header)
2行目の引数『lineterminator = '\n'』は、文章の末尾で改行するという意味です。
5:最後にfor文で取得した記事のデータをひとつひとつファイルに書き込むコードを書きます
#記事番号を設定:最初は1にする
i = 1
# for文で記事データをひとつひとつ取得する
for a in website.articles:
#空のリストを設定し、データをこのリストに入れていく
csv_list = []
#appendを使って、記事データを空のリストにひとつひとついれていく
# i=記事番号
csv_list.append(str(i))
#title=タイトル
csv_list.append(a.title)
#url=リンク先
csv_list.append(a.url)
#summary=記事の内容
csv_list.append(a.summary)
#記事のデータを取得したリストをファイルに書き込むコード
writer.writerow(csv_list)
#10記事のデータを取得したらスクレイピングを止めるコード
if i > 10:
break
# ひとつ記事を取得するごとに、記事番号をひとつ追加するコート
i = i + 1
#開いているファイルを閉じるコード/最後はこれを書く
f.close()
スクレイピングは優れた時間術

今回はブルームバーグの記事を例に、記事データの取得から保存までのコードを紹介しました。
しかし、スクレイピングは使い方次第で、1日=24時間という限られた時間を有効に使うことができる優れたツールとなります。
例えば
あなたが、毎日決まった時間にどこかのサイトから特定のデータを収集し、それをまとめている仕事をしているとしましょう。
あなたは毎日データ先にアクセスし、データをコピーし、それらを貼り付け、ミスがないか確認して・・・という作業を繰り返しています。
この作業に毎日1時間かけているとしたら、年間で約200時間から250時間という貴重な時間を単純な作業に費やしていることになります。
しかし、Pythonのスクレイピングさえ覚えてしまえば、たった数秒で毎日の単純作業が終わります。
単純作業をPythonに任せる環境さえ整えれば、節約した時間をあなたにしかできない仕事や趣味に費やすことができます。
そう、スクレイピングは単にデータを効率的に取得するという手段ではなくー
スクレイピングのここがすごい
すぐれた時間節約の術
になり得るのです。
まとめ
まとめ
- Pythonのスクレイピング を使えばWEB上から記事のデータを取得できる
- Pythonではスクレイピング で取得したデータを簡単に保存できる
- Pythonのスクレイピング を使いこなせば『時間節約術』となる
今回でスクレイピングの基本シリーズ(全3回)は終わりです。
全3回の記事がみなさんのお役に立てればうれしい限りです!
注記事項
当サイトのコンテンツを参考に投資を行い、その後発生したいかなる結果についても、当サイト並びにブログ運営者は一切責任を負いません。すべての投資行動は『自己責任の原則』のもとで行ってください。
最後に
Pythonを学びたい方へ
今やPythonは、マーケットの分析に限らず、あらゆる分野で使われているプログラミング言語です。
Pythonを学んでおけば株式の投資に役立つだけでなく、これからのキャリアを形成する上でも力強い武器となるでしょう。
『私もPythonを学んでみたい!』
という人は以下のリンク先をご覧ください。
プログラミングを学ぼう
なぜプログラミングを学ぶ必要があるのか?その理由がわかります。
そして『これがPythonを効率的に学ぶ方法だ!』と、ジェイが自信をもっておすすする効率的な学習方法もわかります。
この記事と出会ったのも何かの縁です。
ぜひチャレンジしてみてください!




