
ーこの記事は5分で読めますー
2月の記事でフォーカスしていること
2月は『Pythonで優良なバリュー株を見つける方法』にフォーカスした記事をアップしています。
具体的にはー
2月のテーマ
PythonでYahoo! finance USからバリュー株投資に必要なデータを取得する方法
について解説しています(全3回)。
第1回と2回の記事については、以下のリンク先からご覧いただけます。
第1回の記事
-

-
【Pythonコード集】第1回 Pythonを使って優良なバリュー株の銘柄を見つけてみよう!
続きを見る
第2回の記事
-
-
【Pythonコード集】第2回 Pythonを使って優良なバリュー株の銘柄を見つけてみよう!
続きを見る
第3回は、Pythonコードの解説編となります。
株価収益率(PER)編は以下のリンク先からご覧いただけます。
第3回の記事:PER編
-
-
【Pythonコード集】第3回 Pythonを使って優良なバリュー株の銘柄を見つけてみよう!PER編
続きを見る
今回は、第3回の続きで『EPS編』となります。
PER編と同じく、Pythonコードの解説が中心となります。
前回の記事と併せて読めば、pandasに関する知識が深まることでしょう。
ぜひ最後までご覧ください!
Pythonを学ぶなら
・独学でガンガンやれる人は『Udemy』へ
初心者の方におすすめのコースがこちら おすすめ度
▶現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Pythonに興味がある人、学ぶことをためらっている人には、このコースをおすすめします。
タイトルにあるとおり、現役のエンジニアの方がPythonの基礎から応用までを丁寧に教えてくれるコースです。
このコースを学習しながら、同時にアウトプットの練習もしていけば、効率よくプログラミングのスキルをアップさせることができます。
・独学が苦手な人は『テックアカデミー』へ
まずは無料カウンセリングで適正を確かめよう おすすめ度
▶無料キャリアカウンセリング
独学が苦手な人は、迷わずプログラミングスクールに行くことをおすすめします。
メンターが的確に指導してくれるからです。
しかしスクールは、人によって合う合わないがあります。
まずは、無料カウンセリングのあるテックアカデミーで『プログラミングの学習ってこんな感じか』ということを体感してください。
▶Pythonコース
テックアカデミーのスタイルが自分に合うと思った方は、Pythonコースを受講してください。
このコースでは、Pythonに関するすべての基本が学べます。
学ぶ期間は、学生 / 社会人を問わず4週間(1ヶ月)がおすすめです。
それ以上だと間伸びして、学習するモチベーションが下がる可能性があるからです。
・機械学習まで視野に入れているならオンラインPython学習サービス『PyQ』へ
基本から機械学習まで体系的に学ぼう おすすめ度
▶オンラインPython学習サービス「PyQ™(パイキュー)」
Udemyと同じく独学でOK!という人は、PyQをおすすめします。
PyQはPythonの基本から統計学、さらには機械学習まで学べる豊富なコースを提供しています。
問題を解く形式で勉強するスタイルなので、インプットとアウトプットのバランスが絶妙なカリキュラムとなっています。
▶【PyQ】いよいよ、誰でも機械学習を学べる時代へ
Pythonの基本→統計学の順で学んだあと、機会学習にチャレンジすると効率的に『データ分析の何たるか』を学ぶことができます。
第3回目のサマリー
- pandasでデータを取得する方法
- pandasでデータを処理する方法
- matplotlibでチャートを描画する方法
- 効率的なPython学習について
今回の記事の対象者
こんな方におすすめ
- プログラミング言語『Python』に興味がある人
- Pythonで株価分析に必要なデータを取得したい人
- 取得したデータの処理を学びたい人
- Pythonを学んでみたいけどためらっている人
Pythonコードの解説
早速、本題にいきましょう!
まずは、今回のコードの全体像から。
コードの全体像
・ライブラリからEPSデータの処理まで
#ライブラリのインポート
import pandas as pd
import pandas_datareader as web
import matplotlib.pyplot as plt
#ダウ平均のティッカーコードを取得
ticker_list = pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')
#ティッカーコードのみを抽出
tickers = ticker_list[1].iloc[:, 2]
# EPSのデータを取得
EPS_data = web.get_quote_yahoo(tickers)[['epsTrailingTwelveMonths', 'epsForward']]
# 取得したEPSのデータを降順でソート
EPS_sorted_data = EPS_data.sort_values(by = 'epsForward',
ascending = False)
# フォワードEPSと過去12ヶ月EPSの差分を取る
EPS_sorted_data['Diff'] = EPS_sorted_data.epsForward - EPS_sorted_data.epsTrailingTwelveMonths
# EPSの差分がマイナスになっている銘柄を削除
drop_t = EPS_sorted_data.index[EPS_sorted_data['Diff'] <= 0]
EPS_drop = EPS_sorted_data.drop(drop_t)
・チャートの描画(データの可視化)
# チャートを描画(可視化)
EPS_drop.Diff.sort_values(ascending = False).plot(kind = 'bar',
figsize = (15,7),
grid = True,
color = 'darkblue',
fontsize = 13)
# チャートタイトルの設定
plt.title('EPS Growth Chart', fontsize = 25)
# yラベルの設定
plt.ylabel('EPS Growth', fontsize = 25)
# xラベルの設定
plt.xlabel('Tickers', fontsize = 25)
# x軸のラベルを斜め30度に傾ける
plt.xticks(rotation = 30)
# EPSの平均を描画
plt.axhline(y = EPS_sorted_data.Diff.mean(),
color = 'red',
ls = '--');
全体像がわかったところで、ひとつひとつ確認していきましょう!
最初は、EPSのデータを取得するPythonコードからです!
Code 1:EPSデータの取得
#ライブラリのインポート
import pandas as pd
import pandas_datareader as web
import matplotlib.pyplot as plt
#ダウ平均のティッカーコードを取得
ticker_list = pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')
#ティッカーコードのみを抽出
tickers = ticker_list[1].iloc[:, 2]
それでは、順に解説していきます。
解説1:ライブラリのインポート
まずは、いつもどおりライブラリのインポートからです。
ここは、PER編と同じ解説になります。
import pandas as pd import pandas_datareader as web import matplotlib.pyplot as plt
▷pandas
Python版のエクセルです。データ分析では必須となります。
▷pandas_datareader
Yahoo!finance USから必要なデータを取得できる便利なライブラリです。
こちらもマーケット分析では必須となります。
▷matplotlib
Pythonでチャートを描画する際、必ずと言って良いほど使う可視化ライブラリです。
『matplotlib.pyplot』はよく書くパターンなので覚えておきましょう。
『〜 as 〇〇』と書くことで、以降ではasの後ろの簡略形式でコードを書くことができます。
例:pd、web、plt等々
解説2:ダウ平均のデータを取得
必要なライブラリのインポートが終わったら、次はダウ平均のデータを取得します。
ここもPER編と同じです。
#ダウ平均のティッカーコードを取得
ticker_list = pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')
▷pd.read_html
ダウ平均のデータが載っているサイトに『テーブル形式のデータ』がある場合は、このコードを使うことをおすすめします。
テーブル形式のデータ、というのがポイントです。
取得したデータを変数『ticker_list』に入れましょう。変数名は好きに決めてOKです。
解説3:ティッカーコードのみを抽出
データの取得は、銘柄のティッカーコードがあれば十分です。
ここもPER編と同じです。
#ティッカーコードのみを抽出 tickers = ticker_list[1].iloc[:, 2]
▷ticker_list[1]
まず、上のコードで取得したデータ数を確認すると『14』もあります。
その中で、ティッカーコードに関するテーブルデータは『1』番目にあります。
なお、Pythonでは最初を『0』番目として数えます。
なので、2番目にあたるインデックスやカラムは『1』となります。
よって『ticker_list[1]』とすると、以下のテーブルデータのみが抽出できます。
ダウ平均のテーブルデータ
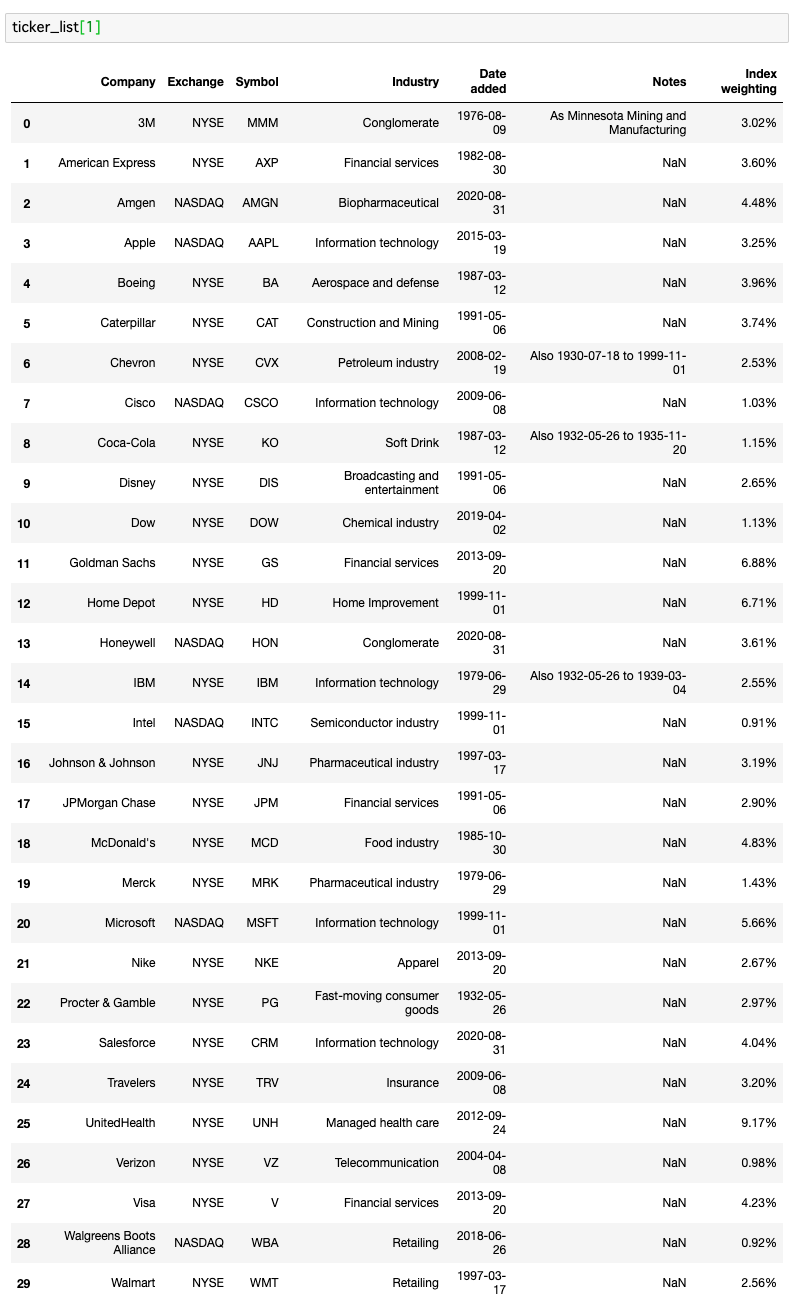
▷ticker_list[1].iloc[:, 2]
上のリストに載っている情報の中で、今回必要なのは銘柄の『ティッカーコード』です。
それにあたるカラム名は『Symbol』です。
Symbolは、0番目、1番目...『2番目』(普通に数えたら3つめ)のカラムとなります。
よって、ticker_list[1]のあとに『.iloc[:, 2]』を追記すると、Symbolのみを抽出することができます。
ilocってなんぞや?
と思う方のために、『iloc』について少しお話しします。
ilocについて
Pandasでは、必要なデータのみをピックアップすることができます
『.iloc』で『 iloc[抽出したい行, 抽出したい列] 』を指定すれば、欲しいデータのみを抽出できます
今回は、全部の行と2番目の列(Symbol)のみを抽出しますのでー
今回のケースでは
全部を抽出する意味の『:』と3つめのカラムの位置を示す『2』
と書くだけで、以下のようにティッカーコードのみを抽出することができます。
Symbolのみのリスト

ティッカーコードを抽出したら、変数『tickers』にデータを格納します。
解説4:EPSのデータを取得
ティッカーコード(Symbol)が取得できれば、あとは一株利益(EPS)のデータを取得するだけです。
# EPSのデータを取得
EPS_data = web.get_quote_yahoo(tickers)[['epsTrailingTwelveMonths', 'epsForward']]
# 取得したEPSのデータを降順でソート
EPS_sorted_data = EPS_data.sort_values(by = 'epsForward',
ascending = False)
▷web.get_quote_yahoo(tickers)
『web』は、pandas_datareaderのことです。
ライブラリをインポートする時に『〇〇as web』としたので、ライブラリ以降のコードはこのように簡略して書くことができます。
『get_quote_yahoo』は、株式の分析に必要なデータを取得する時に使います。
丸カッコの中に、ティッカーコードのデータを格納した変数『tickers』を指定してください。
次は、EPSに関連するデータのみを抽出します。
▷web.get_quote_yahoo(tickers)[['epsTrailingTwelveMonths', 'epsForward']]
最後に[ ]を追加して、この中に抽出したいカラム名を入れるだけで、簡単に特定の情報のみをゲットすることができます。
[ ]を二重にすると、複数のカラム名を一気にゲットすることができます。
今回のケースではー
データのゲット
[['epsTrailingTwelveMonths', 'epsForward']]
と書けば、EPSに関連する2つ(複数)のデータが簡単に取得できるというわけです。
最後に、抽出したデータを変数『EPS_data』に格納しましょう。
解説5:データの並び替え
▷sort_values
『sort_values』は、データを昇順 / 降順で並び替える時に使います。
どの銘柄が割高 / 割安なのか?を簡単に判別するため、変数『EPS_data』を並び替えてみましょう。
並び替えの軸は『12ヶ月先の予想EPS(epsForward)』です。
そして並び替える順番は『降順』です。
やり方は簡単。
以下の引数を設定するだけです。
sort_valuesの引数
- by:並び替えの軸となるカラム名を入力
- ascending:True(昇順)/ False(降順)
最後は、変数『EPS_sorted_data』に取得&抽出したデータを格納してください。
そうすると、以下の結果が表示されます。
実行結果

カラム右の予想EPS(epsForward)を軸に、降順(大きい値→小さい値の順)でデータフレームが表示されていることがわかります。
Code 2:EPSの差分を計算
一株利益(EPS)などの利益に関するデータを見る時に重要なことはー
重要なこと
利益の成長性
を確認することです。
今回のEPSでいうなら、過去12ヶ月のEPSと比べて、今後12ヶ月のEPSは増加(成長)するのか?増加(成長)しないのか?をチェックします。
では、どうやってそれをやるのか?
やり方は簡単です。
下のことをするだけです。
やるべきこと
過去と予想の差分を計算する
では、Pythonコードをみてみましょう。
解説1:EPSの差分を計算
# 今後12ヶ月の予想EPSと過去12ヶ月のEPSの差分を計算 EPS_sorted_data['Diff'] = EPS_sorted_data.epsForward - EPS_sorted_data.epsTrailingTwelveMonths
▷EPS_sorted_data. 〇〇
変数『EPS_sorted_data』の後に、抽出したいカラム名をつけると、カラムに対応したデータが取得できます。
▷変数.epsForward − 変数.epsTrailingTwelveMonths
次に、上のコードのように予想(epsForward) から 過去(epsTrailingTwelveMonths)の値を引き算するだけです。
▷EPS_sorted_data['Diff']
最後に変数『EPS_sorted_data』を格納します。
ここでのポイントはー
ポイント
変数の後ろに[ ]を付けて、その中に新しくカラム名を設定する
ことです。
こうすると、新たなカラム名の箇所に『予想(epsForward)ー過去(epsTrailingTwelveMonths)』の結果が格納されます。
実行してみましょう。
実行結果

一番右に差分を意味する『Diff』というカラムが新しく追加されていることがわかります。
そのDiffカラムに、引き算の結果が反映されています。
解説2:EPS成長がマイナスの銘柄を削除
投資の対象となるのは、将来も収益が伸びる可能性のある銘柄です。
よって、予想EPSと過去のEPSの差分(Diff)がマイナスなっている銘柄を投資の対象から外します。
Pythonなら、たった1行で必要なデータだけを残し、不要なデータを削除することができます。
以下は、その一例です。
# EPSの差分がゼロ以下の銘柄を抽出 drop_t = EPS_sorted_data.index[EPS_sorted_data['Diff'] <= 0] # EPSの差分がマイナスの銘柄をデータフレームから削除 EPS_drop = EPS_sorted_data.drop(drop_t)
▷EPS_sorted_data.index
最初に『EPS_sorted_data』のインデックス、つまり銘柄のティッカーコードを抽出します。
変数『EPS_sorted_data』の後に、『.index』とするだけで簡単にインデックス(ティッカーコード)のデータが抽出できます。
▷[EPS_sorted_data['Diff'] <= 0]
ここがポイントです!
今回は、差分(Diff)がマイナスの銘柄をデータフレームから削除することが目的です。
よって、『['Diff'] <= 0』とすることで、『Diffがゼロ以下の銘柄だけ』を削除することができます。
最後は、変数『drop_t』に削除したいインデックスのデータを格納してください。
▷EPS_sorted_data.drop(drop_t)
削除したいティッカーコードを抽出したら、あとはそれらをデータフレームから取り除くだけです。
『drop』を使えば、削除したいデータのみをデータフレームから取り除くことができます。
引数に、削除するインデックスデータが格納されている変数『drop_t』を入れてください。
最後に、変数『EPS_drop』にマイナス差分が削除されたデータを格納します。
上のコードを実行すると、以下の結果が表示されます。
実行結果
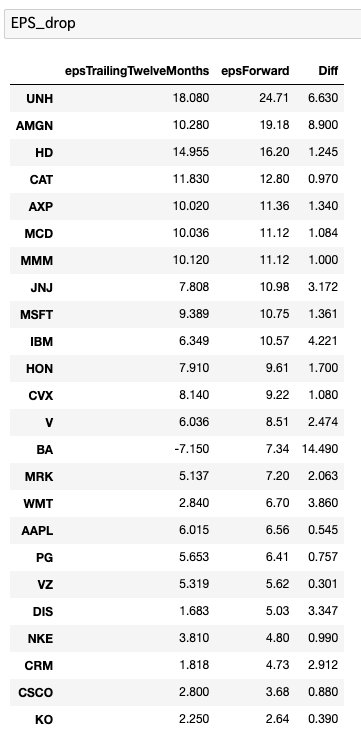
EPSの成長がマイナスの銘柄のみが削除されていることがわかります。
解説3:チャートで可視化
数値だけでなく、チャートでもデータの特徴を確認することは『データ分析の基本』です。
よって、最後にEPSの差分(Diff)を軸に降順でソートしたデータをチャートに描画してみましょう。
# チャートであらためて確認
EPS_drop.Diff.sort_values(ascending = False).plot(kind = 'bar',
figsize = (15,7),
grid = True,
color = 'darkblue',
fontsize = 13)
# チャートタイトルの設定
plt.title('EPS Growth Chart', fontsize = 25)
# yラベルの設定
plt.ylabel('EPS Growth', fontsize = 25)
# xラベルの設定
plt.xlabel('Tickers')
# x軸のラベルを斜め30度に傾ける
plt.xticks(rotation = 30);
▷EPS_drop.Diff.sort_values
変数『EPS_drop』から『Diff』だけを抽出し、その後に『sort_values』で並び替えるコードを書きます。
そしてsort_valuesの引数を『ascending = False』とすれば、Diffを軸に降順でデータの並び替えが完了します。
▷.plot
データを降順で並び替えたら、あとは『.plot』で可視化するだけです。
細かいデザインは、以下の引数で設定しましょう。
plotの引数
- kind:チャートの種類を設定
- figsize:チャートの縦/横サイズを設定
- grid:グリッドラインの有無を設定
- color:色を設定
- fontsize:フォントサイズを設定
▷plt.title('EPS Growth', fontsize = 25)
『plt.title』で、チャートのタイトルを設定できます。引数にタイトル名を入れてください。フォントサイズ(fontsize)も自由に設定できます。
▷plt.ylabel('EPS Growth', fontsize = 25)
『plt.ylabel』で、y軸のタイトルを設定できます。引数にタイトル名を入れてください。フォントサイズ(fontsize)も自由に設定できます。
▷plt.xlabel('Tickers', fontsize = 25)
『plt.xlabel』で、x軸のタイトルを設定できます。引数にタイトル名を入れてください。フォントサイズ(fontsize)も自由に設定できます。
▷plt.xticks(rotation = 30);
『plt.xticks』で、x軸の文字の傾きを設定できます。引数の『rotation』で傾きの度合いを調整できます。
上のコードを実行すると、以下のチャートが描画されます。
実行結果
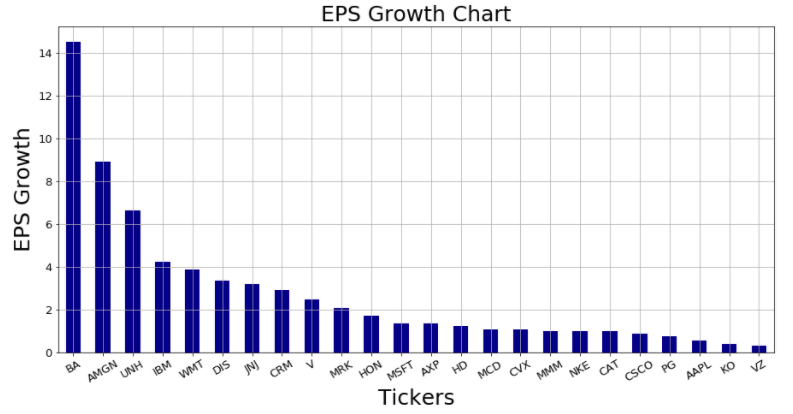
2022年2月18日時点
銘柄によって、EPSの成長度合いが全く違うことがわかります。
おまけ
上のチャートに差分(Diff)の平均をラインで描画してみましょう。
そうすることで、ダウ平均に採用されている銘柄のうち、どの企業の収益性に期待できるのか?という点が、より分かりやすくなります。
plt.axhline(y = EPS_sorted_data.Diff.mean(),
color = 'red',
ls = '--')
▷plt.axhline
『plt.axhline』は、水平線を描画するコードです。
引数で、横線の水準やスタイルを設定します。
plotの引数
- y:横線の水準を設定
- color:色を設定
- is:ラインのスタイルを設定
『y』で横線の水準を決めます。
今回はEPS差分の平均を描画するので、『EPS_sorted_data.Diff.mean()』とすれば、横線がチャート状に描画されます。
『color』で好きな色を設定できます。今回は赤(red)にしました。
『ls』は "line style" の略です。点線を描画したい場合は、この引数で "--" と設定します。
ここまで書いてきたコードに、上の1行を追記して実行すると、以下のチャートが描画されます。
実行結果
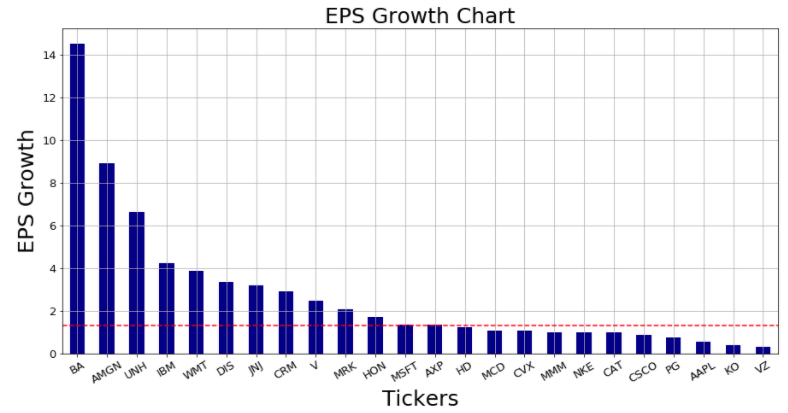 どの銘柄の業績が今後も期待できるのか?が、赤いラインひとつでより明確にわかるようになりましたね。
どの銘柄の業績が今後も期待できるのか?が、赤いラインひとつでより明確にわかるようになりましたね。
Pythonを効率よく学ぶ方法
 Pythonって便利だな!
Pythonって便利だな!
私もPythonを学んでみたい!
今回の記事を読んでそう思われた方は、以下のリンク先をご覧ください。
Pythonを学ぶメリットがわかります。
そして、『これがPythonを効率的に学ぶ方法だ!』と自信をもっておすすめする学習方法について解説しています。
▼ 本気でPythonを学びたいなら ▼
Pythonを学ぼう
独学OKの人ならUdemyで学ぼう!
以下では、オンライン学習プラットフォームの『Udemy』が提供している数多くのPythonコースの中でも、実際にジェイが受講して『これはよかった!』と思うコースをピックアップしました。
なおUdemyでは、受講したコースにあなたが満足しない場合、30日以内なら返金を申請することができます。
このため、安心していろんなコースを受講することができます。
ぜひチャレンジしてみてください!
▼ UdemyおすすめのPythonコース ▼
・Pythonの基礎から応用まで一気に学ぶならこのコース おすすめ度
▶現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
この記事の冒頭でも紹介しましたが、Pythonに興味がある人、学ぶことをためらっている人には、このコースをおすすめします。
タイトルにあるとおり、現役のエンジニアの方がPythonの基礎から応用までを丁寧に教えてくれるコースです。
このコースを学習しながら、同時にアウトプットの練習もしていけば、効率よくプログラミングのスキルをアップさせることができます。
・Python、ファイナンス、英語を一気に学ぶ ”欲張りコース” おすすめ度
▶Python for Finance: Investment Fundamentals & Data Analytics
![]() ※このコースには日本語の字幕がついています。
※このコースには日本語の字幕がついています。
Python、ファイナンスそして英語の力を同時にレベルアップするコースとしては、Udemy最高のクォリティーです。
ジェイもこのコースで学び、今も復習で使っています。
まとめ

まとめ
・pandasを使えばYahoo!finance USから簡単に情報を取得できる
・pandasを使えば簡単にデータの処理ができる
・matplotlibを使えば可視化してデータの分析ができる
今回は以上です。
最後までお読みいただき、ありがとうございました!
注記事項
当サイトのコンテンツを参考に投資を行い、その後発生したいかなる結果についても、当サイト並びにブログ運営者は一切責任を負いません。すべての投資行動は『自己責任の原則』のもとで行ってください。




