
目安:この記事は3分で読めます
Pythonの醍醐味のひとつは、何と言っても統計学を駆使した分析が簡単にできることです。
そこで新たにスタートしたのがー
新しいテーマ
Pythonと統計分析シリーズ
です。
シリーズ第1弾となる今回は、全3回となります。
前編では、Pythonコードの紹介にフォーカスしました。
未読の方は、以下のリンク先へ。
-

-
【Pythonと統計分析】シリーズ第1弾 単回帰分析でウェルズファーゴの株価を予測してみよう!前編
続きを見る
中編となる今回は、前編で紹介したコードの解説となります。
第1弾のテーマ
Pythonの統計分析ライブラリ『Statsmodels』と単回帰分析で株価の予測をしてみよう!コードの解説編
▼ Pythonを効率的に学ぶなら ▼
Pythonを学ぼう
▼ Udemyおすすめの講座 ▼
▶現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
![]() ▶ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門
▶ゼロから始めるデータ分析】 ビジネスケースで学ぶPythonデータサイエンス入門
![]()
この記事の対象となる人
こんな人におすすめ
- Pythonに興味がある人
- Pythonを学びたいと思っている人
- Pythonを使って株価の分析をしたい人
この記事でわかること
結論
- 『Pythonと統計分析シリーズ第1弾』の記事を全部読めば、Pythonを使った単回帰分析の基本がわかる
前回の復習

ターゲットはウェルズ・ファーゴ(WFC)株
今回、分析のターゲットとなる銘柄は、ジェイが実際に投資をしているウェルズ・ファーゴ(WFC)です。
そしてウェルズ・ファーゴ(WFC)の株価は今年入り、アメリカの長期金利(以下では米金利)との連動性が見られます。
この点についての詳細は、前回の記事をお読みください。
単回帰分析で株価を予測
ウェルズ・ファーゴ(WFC)の株価が、米金利の動向に影響を受けていることがわかりました。
そこで今回は、あるひとつの変数(銘柄)の動きがもうひとつの変数(銘柄)の動きにどのくらい影響を与えているのか?
この点を分析するためによく使われるー
今回の分析手法
単回帰分析
を使って、米金利の動向がどのくらいウェルズ・ファーゴ(WFC)の株価に影響しているのか?をみてみます。
ちなみに以下が、今回の分析の概要です。
分析の概要
・説明変数:ウェルズ・ファーゴ
・独立変数:アメリカの長期金利
・分析の期間:2021年以降
・分析の手法:単回帰分析
なお、影響を与える変数(銘柄)を『独立変数』といいます。今回は米金利がそれにあたります。
影響を受ける変数(銘柄)を『説明変数』といいます。今回はウェルズ・ファーゴ(WFC)がそれにあたります。
2つの変数
- 影響を与える変数:独立変数
- 影響を受ける変数:説明変数
ざっと、前回の復習が終わったところでPythonコードをみてみましょう!
Pythonコードの解説

さて、今回の記事で最も重要なPythonコードの解説です。
3つのカテゴリーに分けて解説します。
コードの解説①:ライブラリのインポート
まずは、いつもどおり必要なライブラリをインポートします。
#ライブラリのインポート import pandas as pd import pandas_datareader as web import matplotlib.pyplot as plt %matplotlib inline import datetime
ライブラリの概要
ライブラリの概要
・2行目:Pythonのエクセル版である”pandas” をインポート
・3行目:Yahoo!finance USから価格データを取得するためのライブラリ ”pandas_datareader”をインポート
・4行目:可視化ライブラリの ”matplotlib" をインポート
・6行目:日付を設定する”datetime" をインポート
コードの解説
▶2行目と3行目
過去の記事で説明したとおり、"pandas" はPythonのデータ分析で必須のライブラリです。
『~ as ○○』とすることで、その後のコードを簡略化して書くことができます。
▶4行目
"matplotlib" をインポートする時の定型文みたいなものです。ジェイは『matplotlib.pyplot as plt』と一気に書くことで、matplotlibをインポートするスタイルです。
▶5行目
Jupyter notebook上でグラフやチャートを表示するためのコードです。
これはガチガチの定型文です。書いていくうちに指が覚えます。
▶6行目
”datetime" は日付を設定するためのライブラリです。今回は、データ取得の最終日を設定するためにインポートしました。
コードの解説②:価格データのインポート
さて、ライブラリのインポートが終わりました。
次にやることは『データの取得』です。
いつもどおり、Yahoo!finance USから価格データを取得するコードを書いていきます。
#WFCと米長期金利のデータをインポート
prices = ['WFC','^TNX']
df = pd.DataFrame()
for p in prices:
df[p] = web.DataReader(p, data_source='yahoo',
start='2021-01-02',
end=datetime.date.today())['Adj Close']こ
概要
コードの概要
・2行目:"prices" という変数に価格データを入れる
・4行目:空のデータフレームを用意してそれを "df" という変数に入れる
・6行目以降:ウェルズ・ファーゴと米金利のデータを変数 "df" に入れていく
解説
▶2行目
今回取得したい銘柄のティッカーコードをリスト形式で入れます。
ティッカーコードは、Yahoo!finance USのサイトで銘柄を検索すれば、簡単に確認することができます。
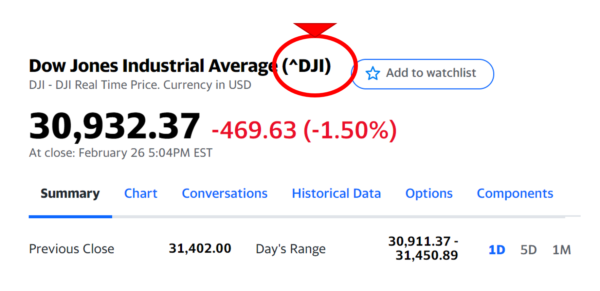
Yahoo!finance USのティッカーコード
今回のティッカーコード
- ウェルズ・ファーゴ:WFC
- アメリカの長期金利:^TNX
なお、ティッカーコードはリスト形式となります。これは、『[ ] でくくる形式』のことです。
他に ( ) でくくるタプルという形式がありますが、ここでは覚えなくて良いです。
プログラミングの学習では、必要なことだけをやること!必要のないことは絶対にやらないこと!
▶4行目
"pd.DataFrame( )" とし、空のデータフレームを設定します。
前もってデータを入れる箱を作っておく、という意味のコードです。
その空箱を変数 "df" に入れるようにします。
▶6行目以降
『for文』ってやつで、順番に価格データを変数に入れるコードを書きます。
for文
for文はデータを順番に認識して、それを変数に入れていくために用いられます。
『for 変数 in オブジェクト:』は、for文の決まった "型" として覚えておきましょう。
今回は変数(p)、オブジェクト(prices)としました。変数名も オブジェクト名も自由に設定できます。
▶7行目以降
ここで”pandas_datareader”のコードを書きます。
4行目で作っておいた空箱の変数 "df" の中に、ウェルズ・ファーゴ(WFC)と米金利のデータを順番に入れるコードを書きます。
pandas_datareaderの引数
・最初にfor文で設定した変数名を入れます。今回はpriceの "p" でしたね。
・data_source:ここではデータを取得するソース元の名前を入れます。
当然 "yahoo" となります。
・start:ここでは取得したい最初の日を設定します。
・end:ここでは取得したい最後の日を設定します。
今回は "datetime" を使ってコードを書いた日を最終日に設定しました。
最後のAdj Closeとは?
最後に ['Adj Close'] と書いてあります。これは『終値だけを取得して』という意味のコードです。
for文で価格のデータを取得する時は、このように書かないとエラーが発生します。
注意してくださいね。
コードの解説③:単回帰分析
さて、いよいよ統計分析のコードです。
#単回帰分析のコード import statsmodels.api as sm x1 = df['^TNX'] y = df['WFC'] x = sm.add_constant(x1) result = sm.OLS(y,x) result.fit().summary()
概要
コードの概要
・2行目:Pythonの統計ライブラリ『statsmodels』をインポート
・4行目:独立変数を "x1"として、ここに米金利のデータをすべて入れる
・5行目:説明変数を "y"として、ここにウェルズ・ファーゴのデータをすべて入れる
・7行目:全要素が1の列を説明変数の先頭に追加するためのコード
・8行目:最小二乗法(OLS)で分析して、結果を変数 "result" に入れるコード
・10行目:OLSの結果を学習させ、結果を表示するコード
解説
▶2行目 ★ここがポイント!
『statsmodels』が、Pythonで単回帰分析を行うライブラリとなります。
なお、『statsmodels.api』は定型文です。ここで覚えておきましょう。『sm』はstatsmodelsの略です。
▶4行目と5行目
独立変数(x1)と説明変数(y)を設定するコードです。
上でも述べたように、影響を与える独立変数には米金利のデータを入れます。
一方、影響を受ける説明変数にはウェルズ・ファーゴ(WFC)のデータを入れます。
変数名は好きにしてOKです。
一般的には、独立変数を "x" 、説明変数を "y" とすることが多いですね。大文字か小文字かは個人の好みによります。
▶7行目
"add_constant( )" は回帰分析で絶対に必要な定型文です。これを書かないとPythonでは分析ができません。
カッコの中には独立変数を入れます。
▶8行目
"OLS(y,x)" で単回帰分析を行うコードです。カッコの中には(説明変数y、独立変数x)の順で入れます。そうすることで、米金利の動きがウェルズ・ファーゴ株に与える影響度合いを計算することができます。
▶10行目
最後に "変数名.fit()" でOLSに基づいて学習させます。そして ".summary()" で学習した結果を表示します。
8行目のOLSって何?

OLSとは?
今回の単回帰分析で使った『OLS』とは、Ordinary Least Squaresの略称です。
日本語では『最小二乗法』といいます。
最小二乗法とは?
『最小二乗法』は回帰分析の時、よく使われる手法のひとつです。
実際の値と回帰分析で計算された値には必ず誤差が生じます。
その誤差を二乗し、かつ全部足した値を最小にすることで、データに当てはまりの良い『直線』を求める分析の手法です。
この直線のことを『回帰直線』といいます。
回帰直線は『y = ax + b』という一次関数の関係にあります。
まぁ、言葉だけではわかりずらいですよね。
以下の図を見てください。
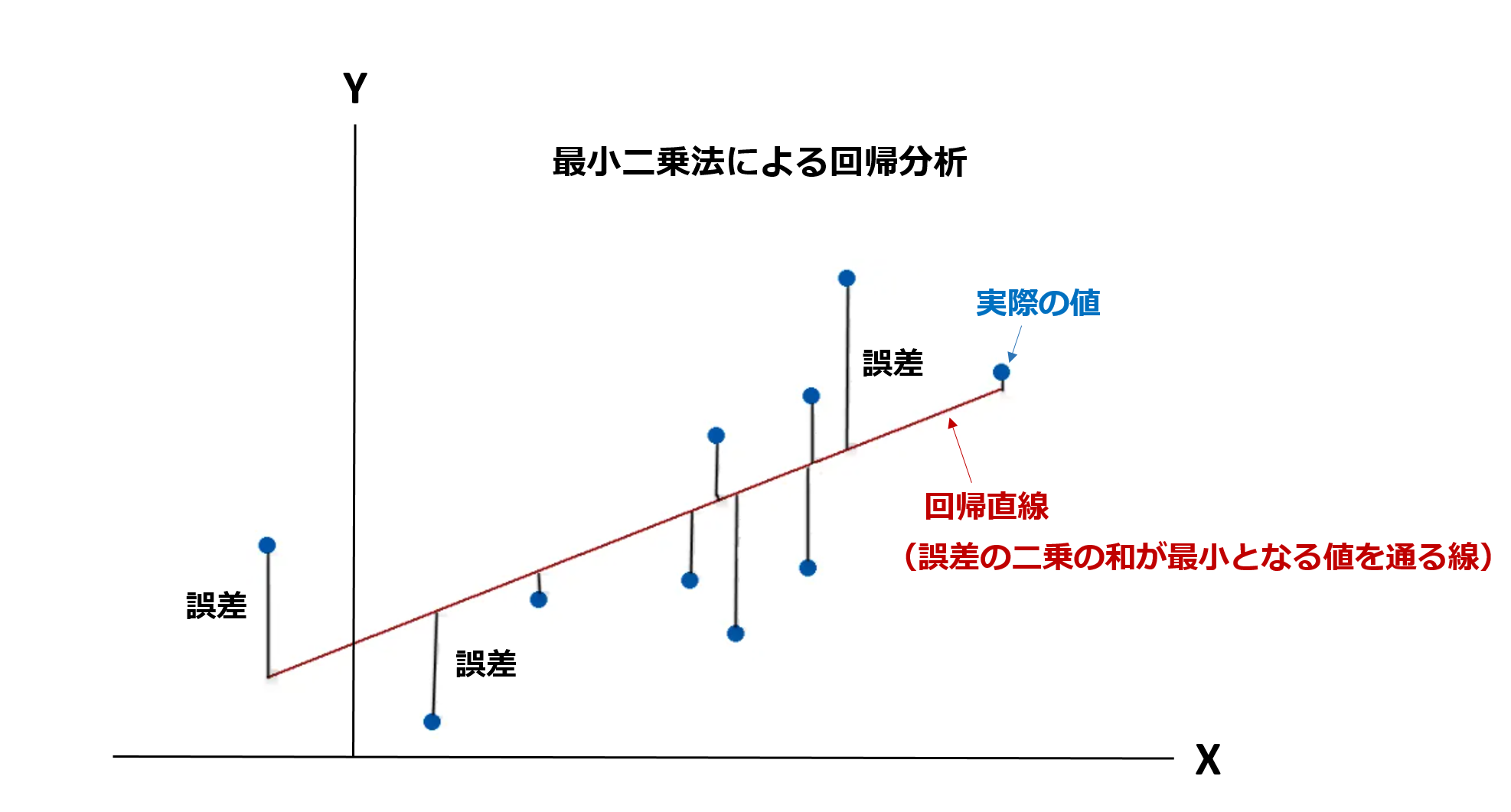
最小二乗法による回帰分析のチャート
各々の実際の値(今回はウェルズファーゴの株価と米金利の水準)と回帰分析の結果描かれた直線には、必ず誤差が生じていることがわかります。
この各誤差が最も小さい値になるよう描かれた赤いラインが『回帰直線』です。
初心者の方は、『最小二乗法を使って単回帰分析をするとこんな図になるんだ』ということだけ覚えておけば十分です。
結果の見方
最後に10行目のコードで表示された結果の見方について確認しましょう。
結論から言いますと、初心者の方が見る項目は以下の4つで十分です。
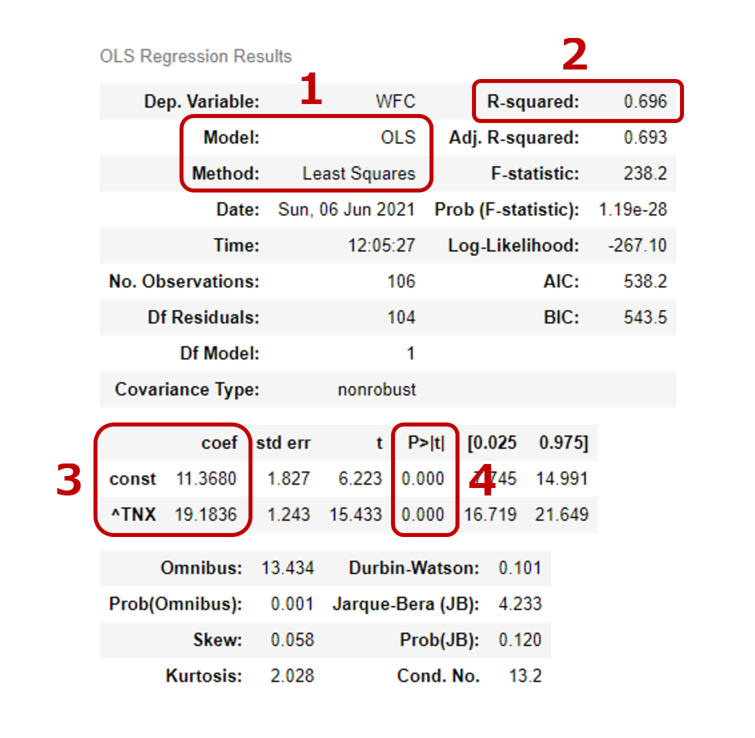
単回帰分析の結果
一覧表の見方
1番目
ここでどんな分析をしたのか?を確認できます。
上でも述べた通り、今回はOLS(最小二乗法)を使いしましたので、OLSとLeast Squaresが表記されています。
2番目
『R-squared』は、分析の正確さを示します。1に近いほどその分析が正確であることを示します。
今回は『0.69』と比較的高い値となっています。今回の分析の精度が、それなりに信頼できることが確認できました。
3番目
・"coef" の『const』は、直線とY軸が交錯する水準のことです。
いわゆる『切片(b)』というやつですね。
上の図を見ればわかるとおり、直線は必ずY軸とクロスします。
今回クロスした値は『11.368』となります。
・『^TXN』は、アメリカ長期金利のティッカーコードです。
『19.1836』という数値は、アメリカの長期金利が1%動いたら、ウェルズ・ファーゴ(WFC)の株価は約19ドル動く可能性があるという意味です。
4番目
・『P>』は、3番目で計算された値(coef)が、統計的に有意かどうかを判断するための値です。
一般的に5%(0.05)以下ならば、統計的に有意と判断します。
今回は『0』ですので、3番目の値は両方とも統計的に有意と判断できます。
ちなみに、『統計的に有意にある』とはー
分析で計算された値と実際の値の差は偶然発生した誤差ではなく意味のある誤差である
ということです。
ごくごく簡単に言えば、p値が5%以下ならば分析結果は統計的に使えますよ、ということです。
統計学を学ぼう

今回は、ジェイなりに統計分析について分かりやすく説明してきました。
しかし、統計学を理解するためには、やはりきちんとした勉強が必要だと思います。
そしてジェイは、統計学の勉強こそ学生、社会人の方を問わずすべての人が一度は学ぶべき分野だと考えています。
その理由はいくつかありますが、ジェイが統計学をすすめる理由はー
統計学をすすめる理由
感情抜きで客観的に物事が見れるから
です。
しかし、この記事を読んでわかるとおり、統計学を理解するためにはある程度の勉強が必要です。
初心者の方なら、なおさらです。
今回の記事を読んでー
『統計学を学びたい!』
『特に基本から学びたい!』
と思う人にジェイは以下の本をおすすめしています。
おすすめ本
初心者の方は、まず『絵』から入ってください。これは鉄則です。
なぜか?それは、先に統計学の専門用語とか数式とかを見ると、100%挫折するからです。
『マンガでわかる統計学 素朴な疑問からゆる~く解説』を先に読めば、挫折率をグッと下げることができます。
この本の特徴
・可愛らしい絵で統計学とは何か?ということを分かりやすく説明している
・統計学を扱っているわりにページ数は少ない。だからすぐに読める
・赤文字や赤線で引かれた箇所を集中的に読むだけでも統計学のイメージがつかめる
上の本を読んだら、いよいよ『本番』です。
次は『コア・テキスト統計学』で、統計学の基本を学んでください。
特徴
・統計学の基本から詳しく解説している
・統計学で必要な数学の知識をちゃんと教えてくれる
・現実の社会に関連した多くの問題が掲載されている
・詳しい回答が書かれている
『コア・テキスト統計学』を読破すれば、統計検定の2級に合格できると言われています。
ジェイも上2つの本を読んで統計学を勉強してきました。
なので、自信を持っておすすめすることができます。
この記事と出会ったのもの何かの縁です。
Pythonだけでなく統計学にもチャレンジしてみてください!
▼独学が苦手な人はテックアカデミー▼
▶現役エンジニアのパーソナルメンターからマンツーマンで学べる
![]()
▶データサイエンスコース
![]()
まとめ
1:Pythonを使えば単回帰分析が簡単にできる
2:統計ライブラリとしてよく使うのが『statsmoels』である
3:『最小二乗法』は単回帰分析でよく使う分析手法である
4:統計学はすべての人が学ぶべき分野。2冊のおすすめ本あり
Pythonを学びたい方へ
今やPythonは、あらゆる分野で使われているプログラミング言語です。
Pythonを学んでおけば株式の投資に役立つだけでなく、これからのキャリアを形成する上でも力強い武器となるでしょう。
『私もPythonを学んでみたい!』
という人は以下のリンク先をご覧ください。
▼ Pythonを効率的に学ぶ方法を知りたいなら以下をクリック ▼
Pythonを学ぼう
なぜプログラミングを学ぶ必要があるのか?その理由がわかります。
そして、『これがPythonを効率的に学ぶ方法だ!』と自信をもっておすすめする学習方法について解説しています。
この記事と出会ったのも何かの縁です。
ぜひチャレンジしてみてください!
注記事項
当サイトのコンテンツを参考に投資を行い、その後発生したいかなる結果についても、当サイト並びにブログ運営者は一切責任を負いません。すべての投資行動は『自己責任の原則』のもとで行ってください。




