
ーこの記事は3分で読めますー
前編
前編の記事では、プログラミング言語のPythonを使ってー
前編の記事
Yahoo! finance USから今後も成長が期待できる高配当銘柄のピックアップ
を試みました。
未読の方は、以下のリンク先からご覧ください。
-

-
【Pythonコード集】配当利回りとEPS成長率で有望な銘柄をピックアップしてみよう! 前編
続きを見る
今回は、前回の記事で用いたPythonコードの解説編となります。
前編とあわせて読めば、Yahoo! finance USのデータをより有益に使えるようになります。
コーヒーでも飲みながら、ぜひ最後までご覧ください!
Pythonを学ぶなら
・独学でガンガンやれる人は『Udemy』へ
初心者の方におすすめのコースがこちら おすすめ度
▶現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Pythonに興味がある人、学ぶことをためらっている人には、このコースをおすすめします。
タイトルにあるとおり、現役のエンジニアの方がPythonの基礎から応用までを丁寧に教えてくれるコースです。
このコースを学習しながら、同時にアウトプットの練習もしていけば、効率よくプログラミングのスキルをアップさせることができます。
・独学が苦手な人は『テックアカデミー』へ
まずは無料カウンセリングで適正を確かめよう おすすめ度
▶無料キャリアカウンセリング
独学が苦手な人は、迷わずプログラミングスクールに行くことをおすすめします。
メンターが的確に指導してくれるからです。
しかしスクールは、人によって合う合わないがあります。
まずは、無料カウンセリングのあるテックアカデミーで『プログラミングの学習ってこんな感じか』ということを体感してください。
▶Pythonコース
テックアカデミーのスタイルが自分に合うと思った方は、Pythonコースを受講してください。
このコースでは、Pythonに関するすべての基本が学べます。
学ぶ期間は、学生 / 社会人を問わず4週間(1ヶ月)がおすすめです。
それ以上だと間伸びして、学習するモチベーションが下がる可能性があるからです。
・機械学習まで視野に入れているならオンラインPython学習サービス『PyQ』へ
基本から機械学習まで体系的に学ぼう おすすめ度
▶オンラインPython学習サービス「PyQ™(パイキュー)」
Udemyと同じく独学でOK!という人は、PyQをおすすめします。
PyQはPythonの基本から統計学、さらには機械学習まで学べる豊富なコースを提供しています。
問題を解く形式で勉強するスタイルなので、インプットとアウトプットのバランスが絶妙なカリキュラムとなっています。
▶【PyQ】いよいよ、誰でも機械学習を学べる時代へ
Pythonの基本→統計学の順で学んだあと、機会学習にチャレンジすると効率的に『データ分析の何たるか』を学ぶことができます。
後編のサマリー
- Pythonコードの解説
- 効率的なPython学習について
今回の記事の対象者
こんな方におすすめ
- プログラミング言語『Python』に興味がある人
- Pythonで株価分析に必要なデータを取得したい人
- 取得したデータの処理を学びたい人
- Pythonを学んでみたいけど ためらっている人
Pythonコードの解説
早速、本題にいきましょう!
まずは、今回のコードの全体像から。
なお、コード画像は左右にスクロールできます。
コードの全体像
#ライブラリのインポート
import pandas as pd
import pandas_datareader as web
import matplotlib.pyplot as plt
#ダウ平均のティッカーコードを取得
ticker_list = pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')
#ティッカーコードのみを抽出
tickers = ticker_list[1].iloc[:, 2]
#配当データを取得
div_data = web.get_quote_yahoo(tickers)[['trailingAnnualDividendRate', 'trailingAnnualDividendYield']]
#見やすくするため、配当利回りのカラムを改めて作成
div_data['Dividend_Yield'] = div_data['trailingAnnualDividendYield']*100
#見やすくした配当利回りのみをピックアップ
div_data = div_data['Dividend_Yield']
#配当利回りが2.5%以下の銘柄(インデックス)をピックアップ
drop_index = div_data.index[div_data<=2.5]
#配当利回りが2.5%以上の銘柄のみを削除
div_data = div_data.drop(drop_index)
#EPSデータを取得
eps_data = web.get_quote_yahoo(tickers)[['epsTrailingTwelveMonths', 'epsForward']]
#EPS成長率のカラムを作成
eps_data['EPS_Growth_Rate'] = ((eps_data.epsForward / eps_data.epsTrailingTwelveMonths - 1) )
#EPS成長率のカラムのみをピックアップ
eps_data = eps_data['EPS_Growth_Rate']
#EPS成長率がマイナスの銘柄(インデックス)のみを抽出
drop_index = eps_data.index[eps_data<=0]
#EPS成長率がマイナスの銘柄(インデックス)のみを削除
eps_data = eps_data.drop(drop_index)
#データを統合し、NaNの銘柄を削除
#ピックアップされたデータを変数『data』に格納
data = pd.concat([div_data, eps_data], axis=1).dropna()
全体像がわかったところで、ひとつひとつ確認していきましょう!
Code 1:ライブラリのインポート
まずは、いつも通りライブラリのインポートからです。
#ライブラリのインポート import pandas as pd import pandas_datareader as web
それでは、順に解説していきます。
解説
▷pandas
データ分析では必須のライブラリです。pandasはPython版のエクセルです。
▷pandas_datareader
Yahoo!finance USから必要なデータを取得できる便利なライブラリです。
こちらもマーケット分析では必須となります。
『〜 as 〇〇』と書くことで、以降ではasの後ろの簡略形式でコードを書くことができます。
例:pd、web等々
Code 2:銘柄ティッカーの取得
ライブラリの次は、銘柄ティッカーのデータを取得します。
#ダウ平均のティッカーコードを取得
ticker_list = pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')
#ティッカーコードのみを抽出
tickers = ticker_list[1].iloc[:, 2]
解説
▷pd.read_html
ダウ平均のデータが載っているサイトに『テーブル形式のデータ』がある場合は、このコードを使うことをおすすめします。
テーブル形式のデータ、というのがポイントです。
色々なサイトがあると思いますが、ウィキペディアのサイトが便利だと思います。
取得したデータを変数『ticker_list』に入れます。変数名はお好みでOK。
▷ticker_list[1].iloc[:, 2]
ticker_listの中には、14のテーブルデータがあります。
テーブルデータの数
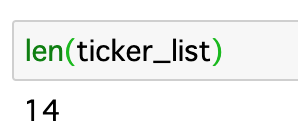
ちなみに『len関数』は、データの数を確かめる時に使います。
その中で、2番目のテーブルデータに銘柄ティッカーの『Symbol』があります。
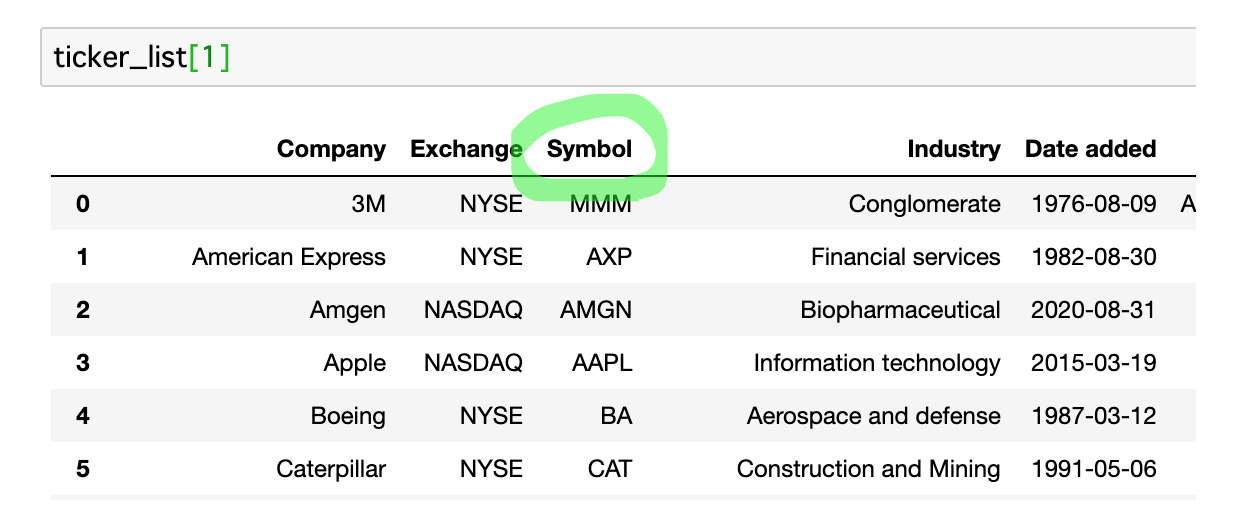
ここで重要なポイントについて!
重要ポイント!
Pythonでは1番目を『0』から数える
なので、2番目にある銘柄ティッカーのデータを抽出するときは『1番目』になります。
この点は、慣れていないとこんがらがるので気をつけましょう!
銘柄ティッカーのデータ『Symbol』の場所がわかったら、次はそのカラムの位置に注目します。
その位置は『3番目』にあります。
よってー
抽出の方法
・ticker_list[1]:2番目のテーブルデータの
・.iloc[:, 2]:3番目のカラムデータだけをすべて
ピックアップして、というコードを書きます。
ilocってなんぞや?
と思っている方がいると思います。
『iloc』について少しお話ししますとー
ilocについて
Pandasでは、必要なデータのみをピックアップすることができます
『.iloc』で『 iloc[抽出したい行, 抽出したい列] 』を指定すれば、欲しいデータのみを抽出できます
今回は、全部の行と3番目のカラム(Symbol)のみを抽出しますのでー
今回のケースでは
全部を抽出する意味の『:』と3つめのカラムの位置を示す『2』
とコードを書きます。
すると、以下のように銘柄ティッカーのデータのみを抽出できます。
実行結果

これで分析の準備が完了しました。
次は、配当と一株利益(EPS)のデータを取得します。
そして、分析の目的に合わせてデータを処理(加工)していきます。
Code 3:配当データの取得と処理
まずは、配当のデータからです。
#配当データを取得 div_data = web.get_quote_yahoo(tickers)[['trailingAnnualDividendRate', 'trailingAnnualDividendYield']] #見やすくするため、配当利回りのカラムを改めて作成 div_data['Dividend_Yield'] = div_data['trailingAnnualDividendYield']*100 #見やすくした配当利回りのみをピックアップ div_data = div_data['Dividend_Yield'] #配当利回りが2.5%以下の銘柄(インデックス)をピックアップ drop_index = div_data.index[div_data<=2.5] #配当利回りが2.5%以下の銘柄を削除 div_data = div_data.drop(drop_index)
配当データについて
Yahoo!finance USが提供している配当データは、以下の3つです。
配当のデータ
-
dividendDate
-
trailingAnnualDividendRate
-
trailingAnnualDividendYield
dividendDateは『配当日』。
trailingAnnualDividendRateは『年間の配当額』。
trailingAnnualDividendYieldは『年間の配当利回り』。
最終的に必要な情報は、最後のtrailingAnnualDividendYieldです。
しかし、複数のカラムデータを取得するコードのコツを紹介したいので、今回は2番目のtrailingAnnualDividendRateも取得します。
解説
▷web.get_quote_yahoo(tickers)
『get_quote_yahoo』で、Yahoo!finance USが提供しているデータの情報を取得できます。
引数には、銘柄ティッカーのデータを入れた『tickers』を設定します。
▷[['trailingAnnualDividendRate', 'trailingAnnualDividendYield']]
次に、配当データのみを抽出します。
やり方は簡単。
web.get_quote_yahoo(tickers)の後に、上のコードをくっつけるだけです。
ここで重要なポイントがあります!
重要ポイント!
複数のカラムデータを抽出するときは [[ ]]と二重にする
こうすることで、複数のカラムデータを一気に取得することができます。
配当のデータのみを抽出して、変数『div_data』に入れます。
▷div_data['Dividend_Yield']
▷div_data['trailingAnnualDividendYield']*100
次は、新しいカラムを作って配当利回りのデータのみを入れます。
変数『div_data』に['Dividend_Yield']を付け加えるだけで、新しいカラム『Dividend_Yield』が簡単に作れます。
div_data['trailingAnnualDividendYield']として、配当利回りのデータのみを抽出して100をかけます。
こうすることで配当利回りが計算され、そのデータがDividend_Yieldという新しいカラム(一番右はし)に反映されます。
実行結果
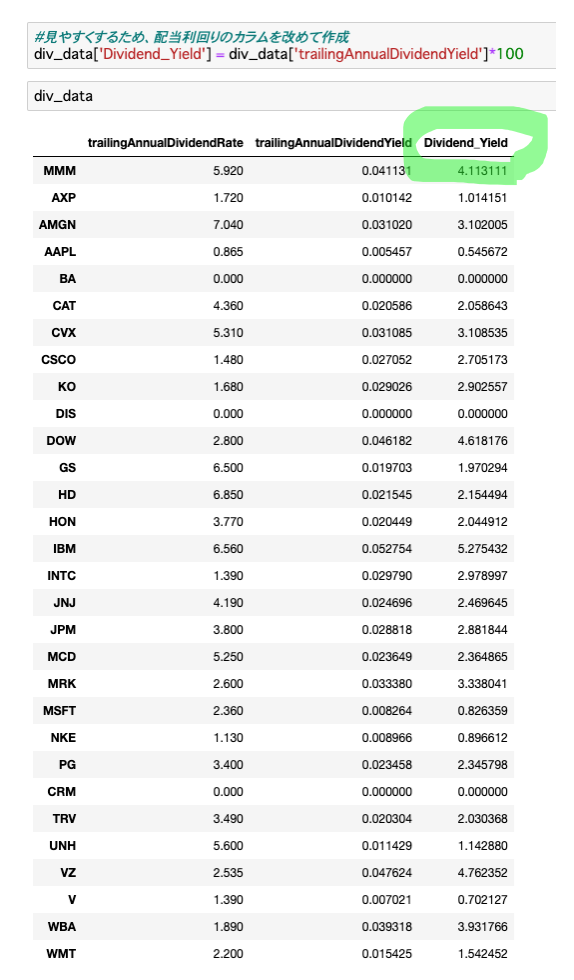
▷div_data = div_data['Dividend_Yield']
配当利回りを計算したら、そのデータのみを編数『div_data』に入れます。
▷div_data.index[div_data<=2.5]
配当利回りのデータのみを抽出した後は、今回の条件に合致しない『配当利回りが2.5以下の銘柄』を削除します。
『div_data.index』とすることで、まずは銘柄ティッカーに絞ります。
次に『 [div_data<=2.5] 』として、2.5%以下の銘柄ティッカーをピックアップします。
そして、変数『drop_index』に2.5%以下の銘柄ティッカーのデータを入れます。
▷div_data.drop(drop_index)
最後にdrop関数を使って、配当利回りが2.5%以下の銘柄ティッカーだけを削除します。
カッコの中に、2.5%以下の銘柄ティッカーのデータを入れた変数『drop_index』を設定します。
そして、変数『div_data』に最終的にピックアップされたデータを入れます。
コードを実行すると、以下の結果が表示されます。
実行結果

一番低い配当利回りがシスコ・システムズ(CSCO)の配当利回り2.7%であることがわかります。
これで配当利回りのデータ処理が終わりました。
次は、EPS成長率のデータ取得と処理をしていきましょう。
Code 4:EPSデータの取得と処理
やることは、これまで述べてきた『データの取得→処理』です。
#EPSデータを取得 eps_data = web.get_quote_yahoo(tickers)[['epsTrailingTwelveMonths', 'epsForward']] #EPS成長率のカラムを作成 eps_data['EPS_Growth_Rate'] = ((eps_data.epsForward / eps_data.epsTrailingTwelveMonths - 1) ) #EPS成長率のカラムのみをピックアップ eps_data = eps_data['EPS_Growth_Rate'] #EPS成長率がマイナスの銘柄(インデックス)のみをピックアップ drop_index = eps_data.index[eps_data<=0] #EPS成長率がマイナスの銘柄(インデックス)のみを削除 eps_data = eps_data.drop(drop_index)
手順
- EPSデータの取得
- EPS成長率の計算とデータの格納
- プラスの成長率のみをピックアップ
Yahoo!finance USが提供しているEPS関連のデータは、以下の4つです。
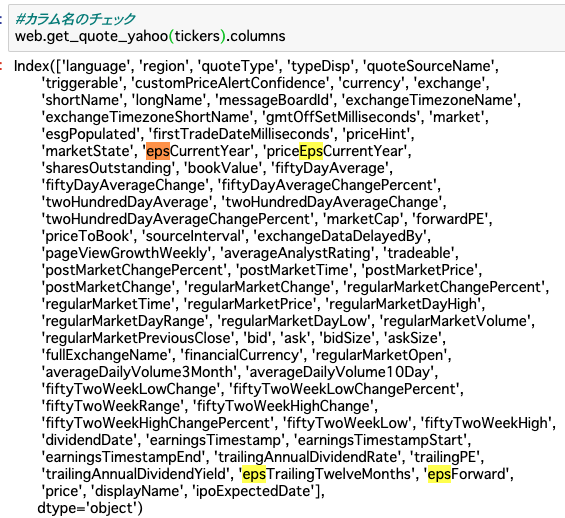
この中で必要な情報は、以下の2つです。
EPSのデータ
-
epsTrailingTwelveMonths
-
epsForward
epsTrailingTwelveMonthsは『過去12ヶ月のEPS』です。
epsForwardは『12ヶ月先の予想EPS』です。
これらのデータだけを抽出するのが、以下のコードです。
▷web.get_quote_yahoo(tickers)[['epsTrailingTwelveMonths', 'epsForward']]
配当関連のカラム名を、EPS関連のカラム名に変更しただけです。
▷((eps_data.epsForward / eps_data.epsTrailingTwelveMonths - 1) )
次に、epsForward(予想EPS)をepsTrailingTwelveMonthsEPS(これまでのEPS)で割り、EPS成長率を計算します。
ここは、算数の式を当てはめればOK。
そして『eps_data['EPS_Growth_Rate']』とし、eps_dataに新たなカラム『EPS_Growth_Rate』をつくって、わかりやすくします。
▷eps_data = eps_data['EPS_Growth_Rate']
変数『eps_data』に、EPS成長率のデータのみのデータ( eps_data['EPS_Growth_Rate'] )を入れます。
▷drop_index = eps_data.index[eps_data<=0]
▷eps_data = eps_data.drop(drop_index)
最後に、EPS成長率がゼロの銘柄を削除します。
ここも条件設定が違うだけで、配当利回りが2.5%以下の銘柄を削除する方法と同じです。
・配当利回りの条件コード:2.5%以下
div_data.index[div_data<=2.5]
・EPS成長率の条件コード:0%以下
eps_data.index[eps_data<=0]
ここまでのコードを実行すると、以下の結果が表示されます。

処理されたデータを降順でソートすると、プラスのデータ(EPS成長率)のみがピックアップされていることがわかります。
Code 5:データの統合
あとは、配当利回りのデータとEPSのデータを統合するだけです。
pd.concat([div_data, eps_data], axis=1).sort_values(by = 'EPS_Growth_Rate', ascending = False)
解説
▷.concat([div_data, eps_data], axis=1)
データを統合する関数『concat』を使います。
引数『axis』を『1』とすることで、列(横)を軸にデータが統合されます。
ちなみに『0』とすると、行(縦)でデータが統合されます。
上のコードを実行すると、以下の結果が表示されます。
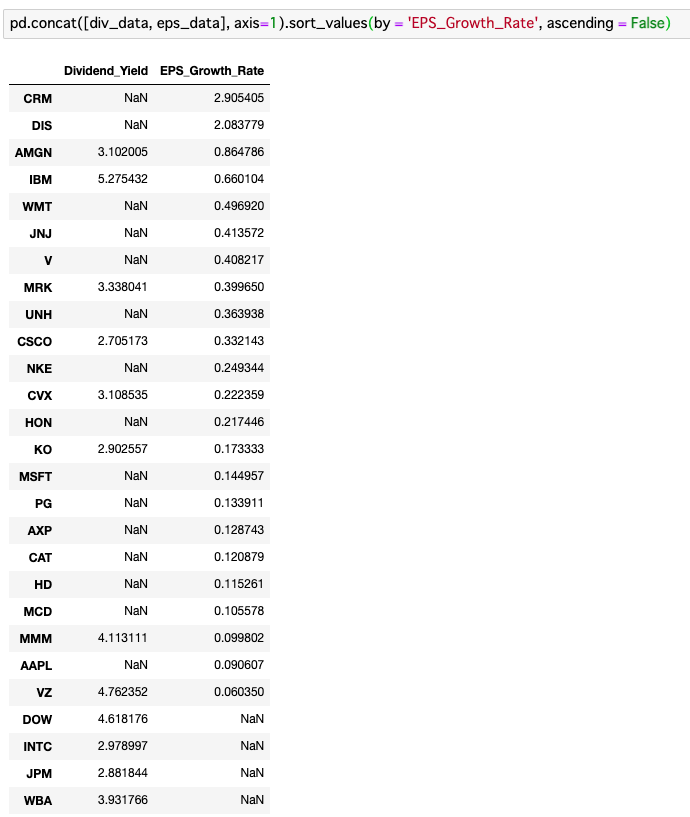
条件設定の結果、配当利回りの条件をクリアした銘柄は『15』あります。
一方、EPS成長率の条件をクリアした銘柄は『26』あります。
よって、お互いのデータを統合すると『NaN』となる銘柄が出てきます。
どちらか一方でもNaNになっている銘柄は、投資対象から外します。
以下のコードで削除します。
data = pd.concat([div_data, eps_data], axis=1).dropna()
『dropna』は、空のデータがある行を一気に削除してくれます。
ここまでのコードを実行すると、以下の結果が表示されます。
実行結果
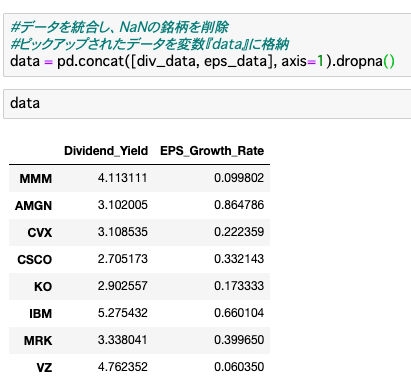
NaNの銘柄(行)が削除され、条件をクリアした配当利回りとEPS成長率のみの銘柄データをピックアップすることができました。
Code 6:データの並び替え
あとは、配当利回りとEPS成長率、どちらかを重視して降順でソートするだけです。
これを行えば、自分の投資をしたい銘柄がよりイメージできます。
# 配当利回りでソート(降順) data.sort_values(by = 'Dividend_Yield', ascending=False) # EPS成長率でソート(降順) data.sort_values(by = 'EPS_Growth_Rate', ascending=False)
上のコードを実行すると、それぞれ以下の結果が表示されます。
実行結果

どちらを重視するかは、あなた次第!
おまけ
上でピックアップした各銘柄の株価は、今年に入り上下に振れる展開が見られます。
3月11日時点での年初来パフォーマンスをみるとー

2022年3月11日時点のパフォーマンス
欧州の地政学リスク(ウクライナ危機)で高騰した原油価格の影響を受け、石油大手のシェブロン(CVX)のパフォーマンス(45.6%)が突出しています。
このブログで優良銘柄として紹介したメルク(MRK、2.1%)とアムジェン(AMGN、1.7%)はプラス圏を維持しています。
一方、IBMは−7%となっています。
Pythonを効率よく学ぶ方法
 Pythonって便利だな!
Pythonって便利だな!
私もPythonを学んでみたい!
今回の記事を読んでそう思われた方は、以下のリンク先をご覧ください。
Pythonを学ぶメリットがわかります。
そして、『これがPythonを効率的に学ぶ方法だ!』と自信をもっておすすめする学習方法について解説しています。
▼ 本気でPythonを学びたいなら ▼
Pythonを学ぼう
独学OKの人ならUdemyで学ぼう!
以下では、オンライン学習プラットフォームの『Udemy』が提供している数多くのPythonコースの中でも、実際にジェイが受講して『これはよかった!』と思うコースをピックアップしました。
なおUdemyでは、受講したコースにあなたが満足しない場合、30日以内なら返金を申請することができます。
このため、安心していろんなコースを受講することができます。
ぜひチャレンジしてみてください!
▼ UdemyおすすめのPythonコース ▼
・Pythonの基礎から応用まで一気に学ぶならこのコース おすすめ度
▶現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
この記事の冒頭でも紹介しましたが、Pythonに興味がある人、学ぶことをためらっている人には、このコースをおすすめします。
タイトルにあるとおり、現役のエンジニアの方がPythonの基礎から応用までを丁寧に教えてくれるコースです。
このコースを学習しながら、同時にアウトプットの練習もしていけば、効率よくプログラミングのスキルをアップさせることができます。
・Python、ファイナンス、英語を一気に学ぶ ”欲張りコース” おすすめ度
▶Python for Finance: Investment Fundamentals & Data Analytics
![]() ※このコースには日本語の字幕がついています。
※このコースには日本語の字幕がついています。
Python、ファイナンスそして英語の力を同時にレベルアップするコースとしては、Udemy最高のクォリティーです。
ジェイもこのコースで学び、今も復習で使っています。
今回は以上です。
最後までお読みいただき、ありがとうございました!
注記事項
当サイトのコンテンツを参考に投資を行い、その後発生したいかなる結果についても、当サイト並びにブログ運営者は一切責任を負いません。すべての投資行動は『自己責任の原則』のもとで行ってください。




