
目安:この記事は3分で読めます。
前回の記事では、PythonとYahoo!finance USを組みあわせて、効率よく企業の収益情報を取得する方法について解説しました。
未読の方は、以下のリンク先からご覧ください。
-

-
【Pythonコード集】Yahoo!financeから米企業の情報を簡単に取得する方法 コード編
続きを見る
今回は、前回の記事で紹介したPythonコードの解説編となります。
記事を読みながら、ぜひあなた自身でトライしてみてください!
今回のテーマ
PythonとYahoo!finance USで米企業の情報を簡単かつ効率よく取得する方法を詳しく解説
この記事の対象となる人
こんな人におすすめ
- 米国企業の情報を効率的に取得したい人
- Pythonを使って分析をしたい人
- Pythonを学びたいと思っている人
この記事でわかること
わかること
- PythonとYahoo!finance USを使って米国企業の情報を簡単に取得する方法
- 効率的にPythonを学ぶ方法(詳細は各リンク先で)
Pythonコードの解説

さっそく本題といきましょう!
まずは、いつもどおり必要なライブラリのインポートからです。
ライブラリのインポート
import pandas as pd import yfinance as yf
解説
はじめに。
Pythonでは『〇〇 as ◇◇』とすると、『〇〇というライブラリを◇◇としてインポートして』という意味になります。
こうすることで、後のコードを簡略化して書くことができます。
▷import pandas as pd
Python版のエクセルであるPandasをインポート
pdで簡略
▷import yfinance as yf
『yfinance』は、Yahoo!finance USからデータを取得するライブラリ
yfで簡略
今回は、上2つのライブラリで十分です。
データの取得
では、次にクラウドストライク(CRWD)のデータを取得してみましょう。
crwd = yf.Ticker('CRWD')
df_crwd = crwd.info
▷yf.Ticker('CRWD')
yf.Ticker('ティッカーコード')で対象銘柄のティッカーを指定します
それを変数『crwd』に入れます
▷crwd.info
変数crwdの後に『.info』を書きます
infoで取得したデータを変数『df_crwd』に入れます
たった2行のコードを書くだけで、クラウドストライク(CRWD)に関する情報が得られます。
結果

Pythonで取得したCRWDの情報
ちなみにいくつデータが取得できるのか?
この点を以下のコードで確認してみましょう。
データサイズを確認する
len(df_crwd)
解説
▷len(df_crwd)
『len』とは”Length”の略で、関数のひとつです
これはー
様々な型のオブジェクトのサイズを取得できる
関数です。
上のコードを実行するとクラウドストライク(CRWD)のデータサイズは、『151』であることがわかります。
データフレーム型にしてみよう
さて、『crwd.info』で取得したデータは、なんだか見にくいですよね。
データの型は『辞書型』です。
辞書型とは
{ キー (key) : 値(value) }で構成されるデータ型のこと
辞書型は、上のようにキーとそれに対する値が対(つい)で表記されます。
例えば、今回のデータからひとつ例としてとってくるとー
{ キー : 値 } = {'symbol': 'CRWD'}
となります。
辞書型は見にくいので、Pythonのエクセル版であるPandasを使って、データフレーム型に転換しましょう。
こうすることで、より見やすくなります。
#まずはキーの取得
keys = []
for key in df_crwd.keys():
keys_list = {key}
keys.append(keys_list)
keys = pd.DataFrame(keys)
#次に値の取得
values = []
for value in df_crwd.values():
values.append(value)
values = pd.DataFrame(values)
解説
今回は、Python初心者の方にわかりやすく理解してもらうため、キー値とバリュー値に分けて、ひとつひとつ情報を取得することにします。
▷keys = []
まずは空のリスト(箱)を用意します
これはデータを格納するための箱です
▷for key in df_crwd.keys():
for文でキーをひとつひとつ取得するコードです
for文とは
・for文を使えば繰り返し処理を行うことができます
for文の型について
・for カウンタ変数 in オブジェクト:
実行したい処理
『変数名.keys()』と書けば、簡単にキーのみを取得することができます
『変数名.keys()』で取得したキーのデータを、カウンタ変数『key』に入れる、というイメージを持ってください
for文の最初のコードを書いた後は、何を実行したいのか?を指定します。
▷keys_list = {key}
実行したいことをコードで書きます
ここは、『辞書型{ }でキー値のみのデータを入力してください』というコードになります
取得したすべてのキーを、いったん変数名『keys_list』に入れます
▷keys.append(keys_list)
次に、変数名『keys_list』でいったん格納していたキーを、for文の上で作っておいた空のリスト『keys』に入れます
リスト型にデータを追加するときはー
.append(追加したいデータ)
と書くだけです。
そして、いよいよリスト型をデータフレーム型へ変換するコードです。
▷pd.DataFrame(keys)
『pd』はpandasの略です
『.DataFrame(データフレームにしたい変数)』と書くだけで、エクセルのような見栄えにデータの型を変換することができます
なお、値(value)のデータをfor文で取得するときはー
・最初に値を入れるための空のリストを作成
・次にオブジェクトを『変数名.values()』にする
・最後にデータフレームへ転換し、値のデータ用の変数に入れる
上の3つを変更するだけです。
キーと値を取得するfor文を実行すると、以下の結果が得られます。
head関数で、最初の5つを確認してみましょう。
結果
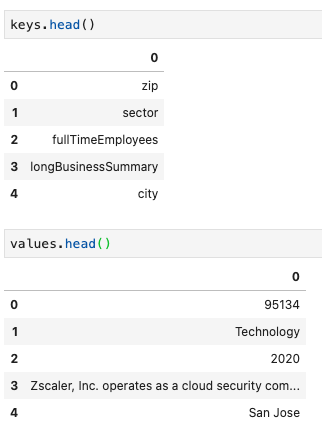
Pythonで取得したCRWDの情報
データフレームの完成形
最後にキーと値のデータフレームをひとつにして、クラウドストライク(CRWD)のデータフレームを完成させます。
data_crwd = pd.concat([keys,values],axis=1)
data_crwd.columns = ('Category', 'Data')
解説
▷pd.concat([keys,values],axis=1)
『pd』はpandasの略です
データを結合する時はー
concat関数
を使います。
concat関数の引数
・最初の引数に結合したいデータフレームの変数名を書く
・2番目の引数に軸(axis)を指定する
concat関数 軸の指定
・axis=0:縦にデータを結合する
・axis=1:横にデータを結合する
今回は『concat([keys,values],axis=1)』としているので、『キーと値のデータフレームを横に結合してください』というコードになります。
▷data_crwd.columns = ('Category', 'Data')
『変数名.columns』とすれば、カラム名を左から順に設定することができます
すべてのデータを確認してみよう
今回のデータサイズは、len関数でチェックしたとおり『151』もあります。
なので、あなたが欲しいデータがどこにあるのか?をチェックするためには、一度データの全体像を確認する必要があります。
しかし、データが多すぎるとPandasは、結果を省略して表示します。
以下のように。
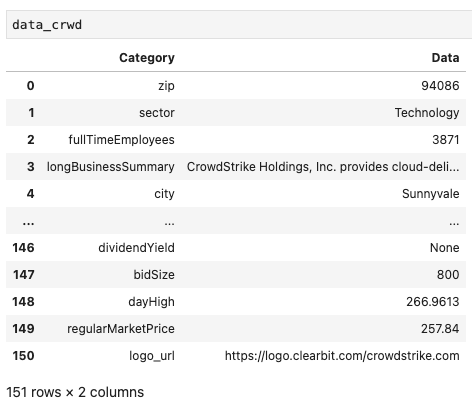
Pythonで取得したCRWDの情報
データの全体像を確認したい場合は、以下のコードを使います。
pd.set_option("display.max_rows", 151)
解説
▷pd.set_option("display.max_rows", 151)
『set_option』は、表示したいデータの数を設定することができる関数です
『"display.max_rows"』の”max_rows”で行を指定しています
そして数を『151』にすることで、すべての行のデータを表示することができます
結果
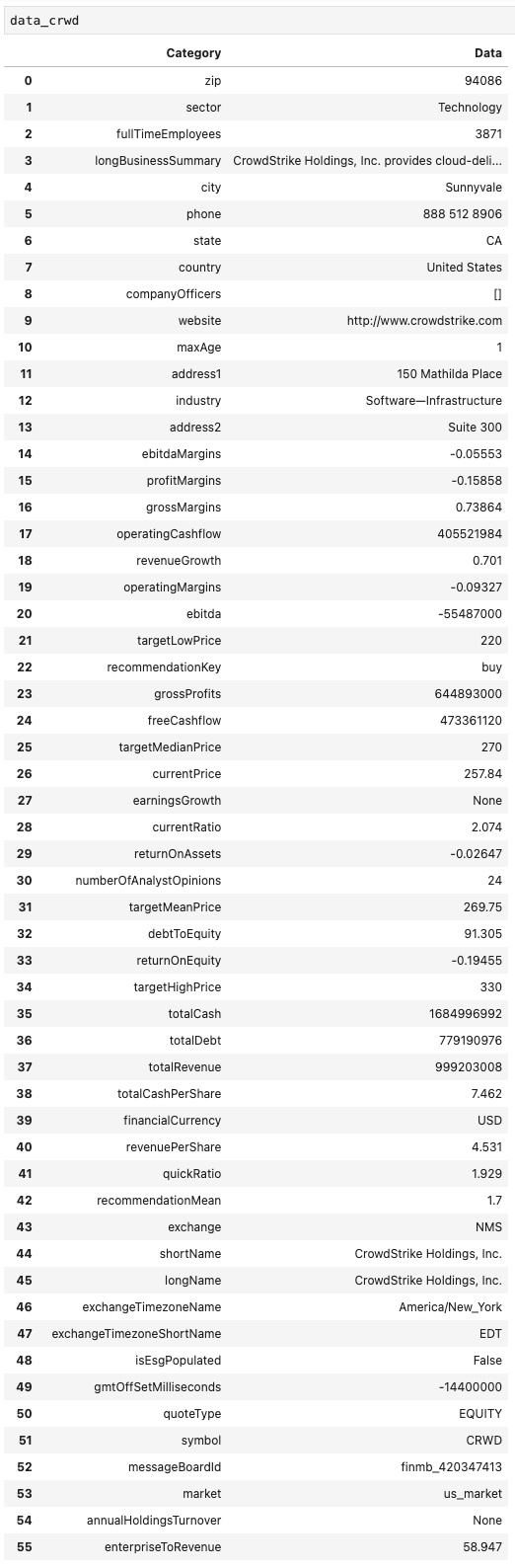
Pythonで取得したCRWDの情報
長くなるので全部は載せませんが、省略されていた箇所が表示されていることが確認できました。
必要なデータをピックアップ
クラウドストライク(CRWD)のデータを取得することができました。
151のデータから、見たい情報だけをピックアップしてみましょう。
今回は、クラウドストライク(CRWD)の収益性に関するデータをピックアップしてみます。
data_crwd = data_crwd[14:25]
解説
▷data_crwd[14:25]
変数名[ : ]と書くだけで、あなたの見たいデータのみをピックアップすることができます
[14:25]とは、『14行から25行目までのデータをピックアップして表示してください』という意味です
Pythonの場合、スタートは『0』です。『1』ではありませんので注意してください
結果
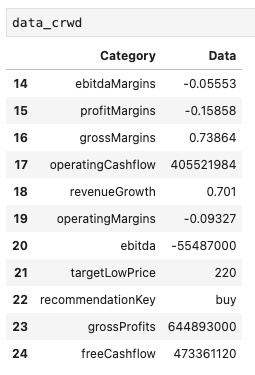
Pythonで取得したCRWDの情報
クラウドストライク(CRWD)の収益性に関するデータのみが表示されました。
比較してみよう
データ分析では比較がとても重要です。
クラウドストライク(CRWD)と同じく、クラウドセキュリティのサービスを提供しているジースケーラー(ZS)のデータを取得してみましょう。
上で書いてきたコードを一気にまとめて表示します。
コード一覧
zs = yf.Ticker('ZS')
df_zs = zs.info
keys = []
for key in df_zs.keys():
keys_list = {key}
keys.append(keys_list)
keys = pd.DataFrame(keys)
values = []
for value in df_zs.values():
values.append(value)
values = pd.DataFrame(values)
data_zs = pd.concat([keys,values],axis=1)
data_zs.columns = ('Category', 'Data')
pd.set_option("display.max_rows", 151)
data_zs[13:24]
data_zs = data_zs[13:24]
クラウドストライク(CRWD)と同じことをしているので、解説は省きます。
上のコードを実行すると、以下の結果が得られます。
結果
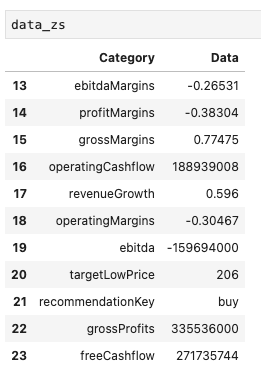
Pythonで取得したZSの情報
同じくジースケーラー(ZS)の収益性に関するデータのみをピックアップできました。
注意点はー
注意ポイント
データの位置がズレている
ことです。
クラウドストライク(CRWD)のデータは、14〜25行目をピックアップしました。
一方、ジースケーラー(ZS)のデータは、13〜24行目となります。
こういったことがあるので、どんな分析でも一度データの全体像をチェックすることをおすすめします。
データの結合
クラウドストライク(CRWD)とジースケーラー(ZS)のデータを簡単に比較するために、収益性のデータを結合しましょう。
df = pd.merge(left = data_crwd, right=data_zs,
on='Category',
suffixes=['_CRWD','_ZS'])
df.set_index('Category',inplace=True)
解説
▷pd.merge( )
共通のデータ列を持っている場合、上で使った『concat関数』よりもー
merge関数
の方をよく使います。
merge関数の引数
・left:左に表示するデータを設定
・right:右に表示するデータを設定
・on:共通項を指定
・suffixes:カラム名の設定
merge関数のポイントはー
共通項を指定する『on』
です。
今回のデータフレームの共通項は『Category』となります。
この『Category』を軸に、左にクラウドストライク(CRWD)のデータ、右にジースケーラー(ZS)のデータを結合することができます。
▷.set_index('Category',inplace=True)
『set_index』を使って、『Category』をインデックスに指定するコードです
『inplace=True』とすれば、新しく変数を設定しなくても変更が反映されます
このコードは好みなので、なくても大丈夫です
上のコードを実行すると、以下の比較データが表示されます。
結果
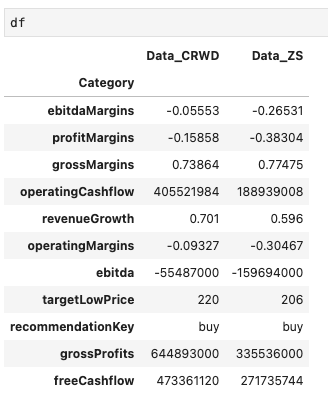
Pythonで取得したCRWDとZSの情報
一番はじめと比べると、かなり見やすくなりましたね!
今回は以上です。
興味のある方は、ぜひコピペして遊んでみてください!
効率よくPythonを学ぶ方法

Pythonを使えば、あらゆる面で効率性が上がります。
実際、今回紹介したコードの『ティッカー』を変えるだけで、Yahoo!finance USが提供しているすべての情報を取り出すことができます。
効率が上がるということは、『効率になった分だけ時間を作り出すことができる』ということです。
これは、人生においてとても重要なことです。
私もPythonを学んで、効率性を上げたい!有意義な時間を作り出したい!という方は、以下のリンク先をご覧ください。
▼ 本気でPythonを学びたいなら ▼
Pythonを学ぼう
なぜプログラミングを学ぶ必要があるのか?その理由がわかります。
そして、『これがPythonを効率的に学ぶ方法だ!』と、ジェイが自信をもっておすすめする学習方法について解説しています。
この記事と出会ったのも何かの縁です。
ぜひチャレンジしてみてください!
独学が苦手な人へ
▼スクールで学ぼう▼
▶現役エンジニアのパーソナルメンターからマンツーマンで学べる
![]()
▶データサイエンスコース
注記事項
当サイトのコンテンツを参考に投資を行い、その後発生したいかなる結果についても、当サイト並びにブログ運営者は一切責任を負いません。すべての投資行動は『自己責任の原則』のもとで行ってください。




